KAIRA 5B Strategy
KAIRA 5B Stratejisi
1. Vision and Approach
KAIRA is not just a standard LLM; it is an AI that mathematically internalizes the morphological structure and cultural depth (idioms, sarcasm, emotion) of the Turkish language.
Key Strategies
- Efficiency-First Architecture: A 5B parameter structure capable of running on mobile devices but with the efficiency of a 3200 ELO chess engine.
- Knowledge Distillation: Intelligence transfer via "Logits" from 9B+ teacher models.
- Dictionary Injection: Integrating a 104k-line custom labeled dictionary into the tokenizer and embedding layers.
1. Vizyon ve Yaklaşım
KAIRA, standart bir dil modelinden öte, Türkçe'nin morfolojik yapısını ve kültürel derinliğini matematiksel olarak içselleştirmiş bir yapay zekadır.
Temel Stratejiler
- Verimlilik Odaklı Mimari: Mobilde çalışabilen, yüksek verimli 5B parametre yapısı.
- Knowledge Distillation (Damıtma): Büyük öğretmen modellerden bilgi transferi.
- Sözlük Enjeksiyonu: 104.000 satırlık özel sözlüğün entegrasyonu.
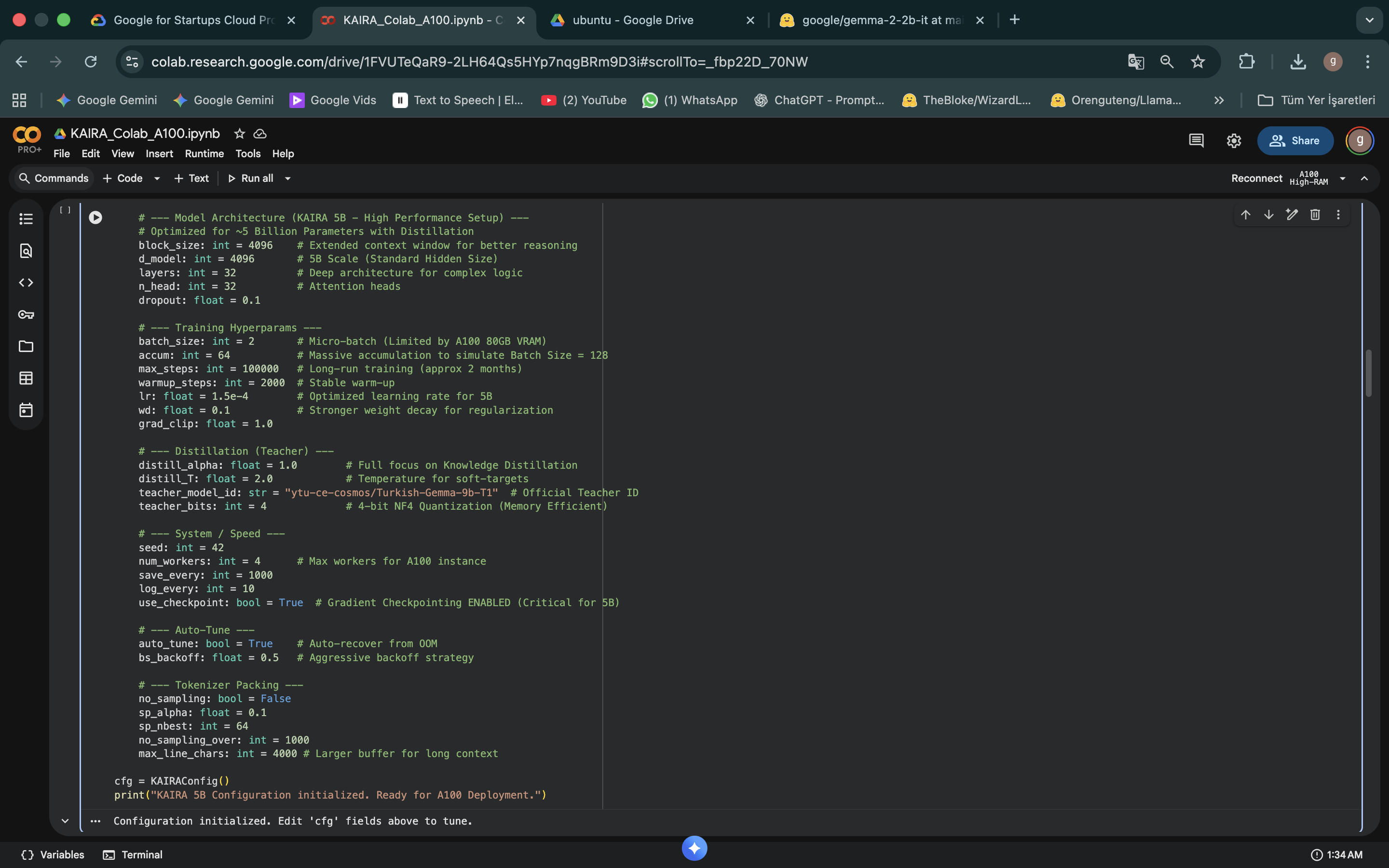
2. Phase 0: Tokenizer Surgery
Before training, the model's vocabulary is modified based on the project's greatest asset: the Custom Dictionary.
- Operation: Multi-word idioms in the 104k dictionary (e.g., "Bambu ağacından takım kim ben kim") are added as single tokens.
- Goal: Ensuring the model perceives idioms as a whole concept rather than fragmented words.
- Smart Initialization: Embedding weights for new tokens are initialized by averaging their constituent words rather than randomly.
2. Faz 0: Tokenizer Ameliyatı
Eğitim öncesi kelime haznesi (Vocabulary), özel sözlüğe göre modifiye edilir.
- İşlem: 104k sözlükteki deyimler tekil token olarak eklenir.
- Amaç: Deyimleri parçalamadan bütüncül (kavram) olarak algılatmak.
- Akıllı Başlatma: Yeni token ağırlıkları, kelimelerin ortalaması alınarak başlatılır.
Dictionary Data Structure
The core of KAIRA's intelligence lies in its structured dictionary data. Here is a raw sample entry representing the depth of a single concept.
Sözlük Veri Yapısı
KAIRA'nın zekasının temeli, yapılandırılmış sözlük verisinde yatmaktadır. İşte tek bir kavramın derinliğini temsil eden ham bir veri örneği.
3. Training Curriculum
To maximize learning capacity, the 150 Billion token dataset is presented in a 4-stage strategy.
Phase 1: Apprenticeship
- Volume: 60 Billion Tokens (First 40%)
- Source: YouTube Transcripts, Clean Web Data.
- Method: Hard Labels (Classic Training). No teacher model.
- Goal: Learning grammar, sentence structure, and fluency.
Phase 2: Journeyman (Transfer)
- Volume: 60 Billion Tokens (Middle 40%)
- Source: Books, Articles, Encyclopedic Knowledge.
- Method: Knowledge Distillation (KL-Divergence). Teacher active.
- Goal: Logic reasoning, cause-and-effect, deep understanding.
Phase 3: Mastery & Culture
- Volume: 25 Billion Tokens (Last 15-20%)
- Source: 104k Custom Dictionary (Weighted) + Quality Dialogues.
- Goal: Emotional intelligence, idiom usage, "One of Us" speaking style. Eliminating hallucinations.
3. Eğitim Müfredatı
150 Milyar tokenlik veri seti, öğrenme kapasitesini artırmak için 4 aşamada sunulur.
Faz 1: Çıraklık (İnşaat)
- Hacim: 60 Milyar Token (İlk %40)
- Kaynak: YouTube, Temiz Web Verisi.
- Yöntem: Klasik Eğitim.
- Amaç: Dilbilgisi ve akıcılık.
Faz 2: Kalfalık (Transfer)
- Hacim: 60 Milyar Token (Orta %40)
- Kaynak: Kitaplar, Makaleler.
- Yöntem: Knowledge Distillation.
- Amaç: Mantık ve derin anlama.
Faz 3: Ustalık ve Kültür
- Hacim: 25 Milyar Token (Son %20)
- Kaynak: 104k Özel Sözlük + Diyaloglar.
- Amaç: Duygusal zeka, "Bizden Biri" gibi konuşma.
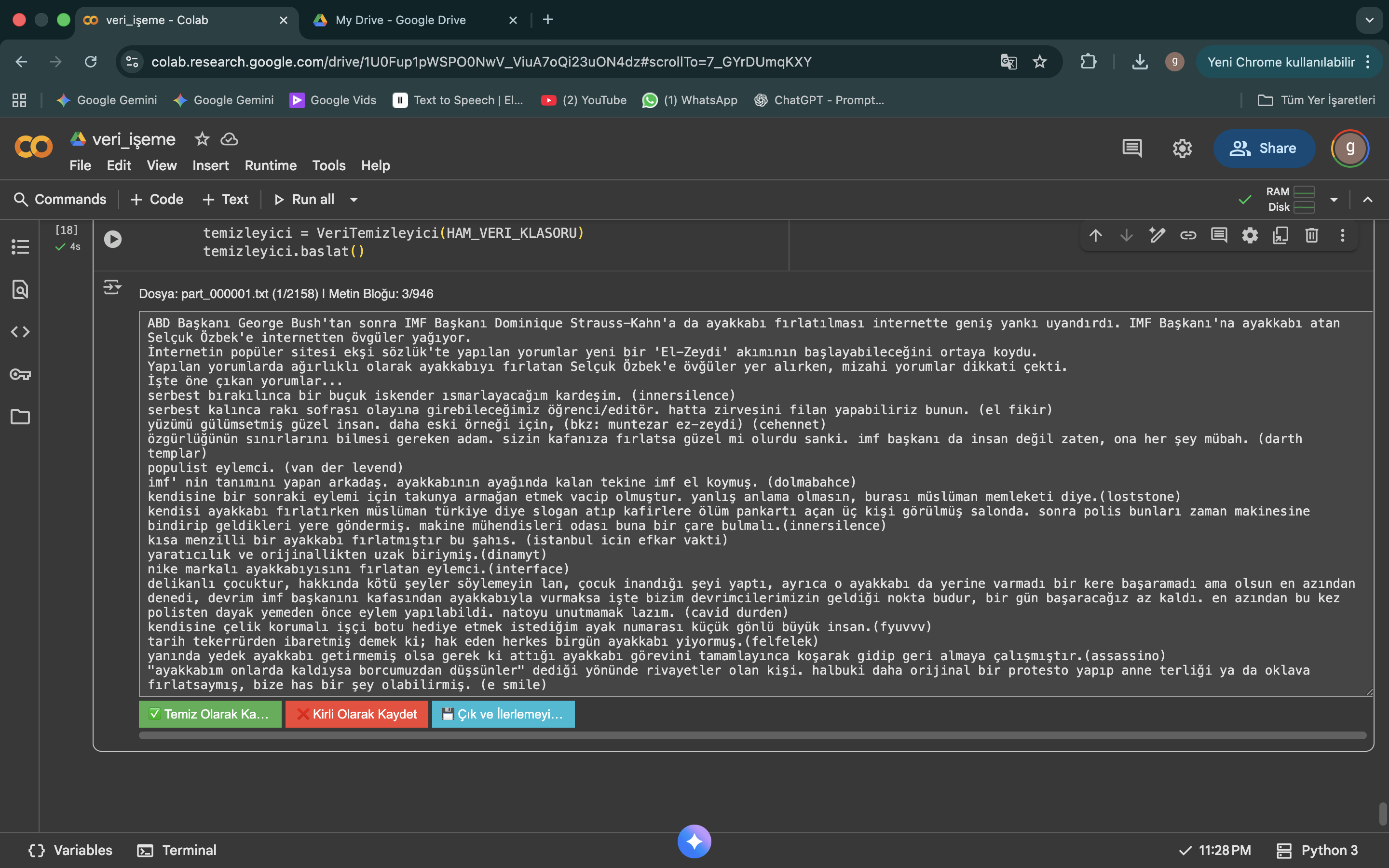
Figure 2: Surgical Data Cleaning Pipeline
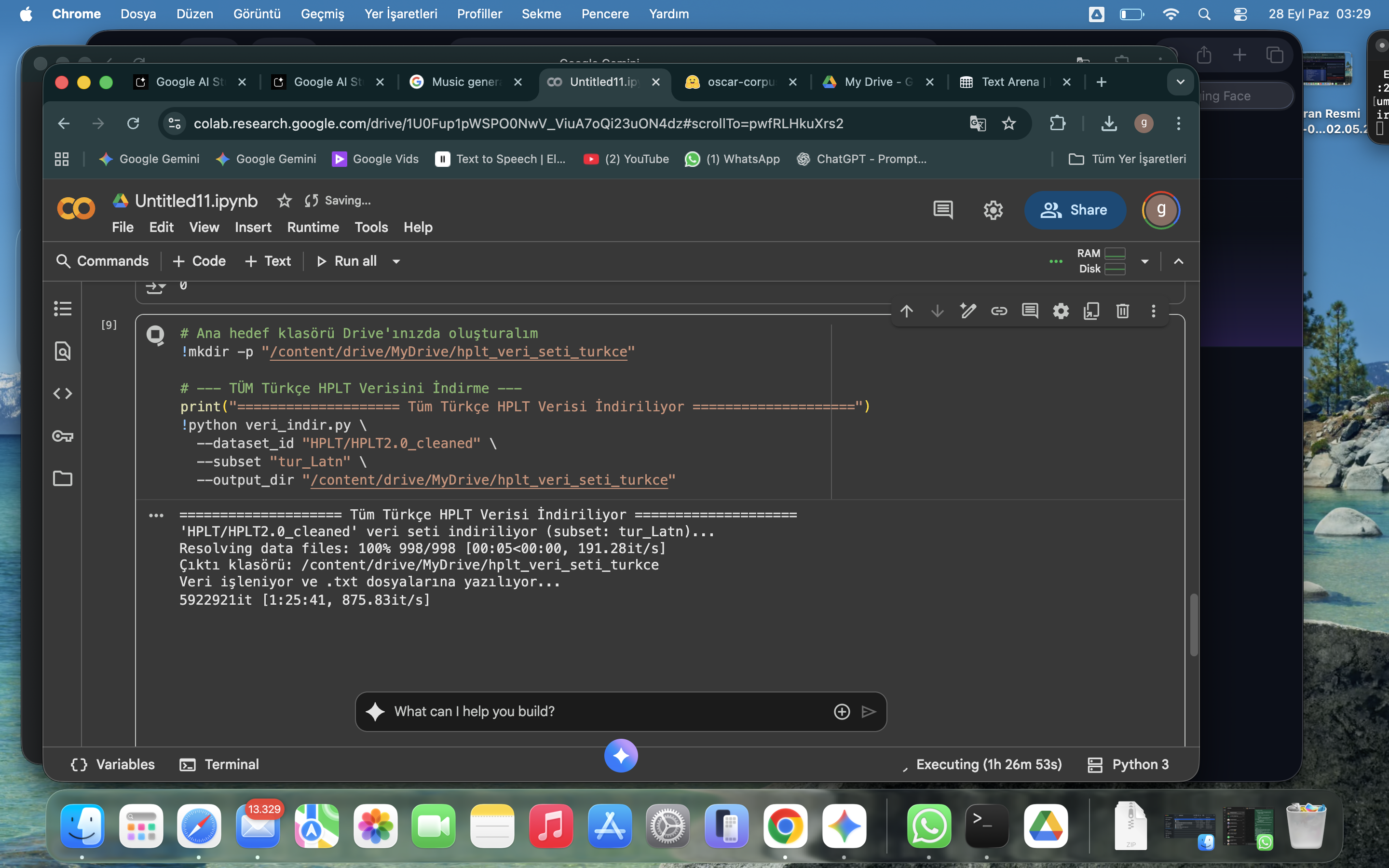
Figure 3: Massive Data Collection Strategy
4. Advanced Tuning: The "Reflection" Protocol
Standard LLMs often hallucinate because they answer immediately. KAIRA is being fine-tuned with a specialized "System 2" dataset that forces the model to think, criticize itself, and correct before outputting a final answer.
We are generating 20,000+ high-quality synthetic samples where the Teacher model demonstrates Self-Correction in both Turkish and English contexts.
4. İleri Seviye Ayar: "Refleksiyon" Protokolü
Standart modeller hemen cevap verdikleri için sıkça halüsinasyon görürler. KAIRA, modele cevap vermeden önce düşünmeyi, kendini eleştirmeyi ve düzeltmeyi öğreten özel bir "Sistem 2" veri seti ile eğitilmektedir.
Öğretmen modelin hem Türkçe hem İngilizce bağlamlarda Öz-Düzeltme (Self-Correction) yeteneğini sergilediği 20.000+ adet yüksek kaliteli sentetik veri üretiyoruz.
Sample Training Data Structure (JSONL) Örnek Eğitim Verisi Yapısı (JSONL)
5. Technical Configuration (A100)
5. Teknik Konfigürasyon
| Parameter | Value |
|---|---|
| Architecture | Gemma-2 (Decoder-Only) |
| Parameter Count | ~5 Billion (5B) |
| Context Window | 4096 Token |
| Hidden Size | 4096 |
| Layers | 32 |
| Attention Heads | 32 |
| Tokenizer | SentencePiece + Custom Tokens |
| Training Precision | BF16 (Bfloat16) |
| Optimizer | AdamW (Fused) |
| Load | ~3 ZettaFLOPs |